


Abstract
There are a variety of methods available to calculate the inhibition constant (Ki) that characterizes substrate inhibition by a competitive inhibitor. Linearized versions of the Michaelis-Menten equation (e.g., Lineweaver-Burk, Dixon, etc.) are frequently used, but they often produce substantial errors in parameter estimation. This study was conducted to compare three methods of analysis for the estimation ofKi: simultaneous nonlinear regression (SNLR); nonsimultaneous, nonlinear regression, “KM,app” method; and the Dixon method. Metabolite formation rates were simulated for a competitive inhibition model with random error (corresponding to 10% coefficient of variation). These rates were generated for a control (i.e., no inhibitor) and five inhibitor concentrations with six substrate concentrations per inhibitor and control. TheKM/Ki ratios ranged from less than 0.1 to greater than 600. A total of 3 data sets for each of threeKM/Ki ratios were generated (i.e., 108 rates/data set perKM/Ki ratio). The mean inhibition and control data were fit simultaneously (SNLR method) using the full competitive enzyme-inhibition equation. In theKM,app method, the mean inhibition and control data were fit separately to the Michaelis-Menten equation. The SNLR approach was the most robust, fastest, and easiest to implement. The KM,app method gave good estimates ofKi but was more time consuming. Both methods gave good recoveries of KM andVMAX values. The Dixon method gave widely ranging and inaccurate estimates of Ki. For reliable estimation of Ki values, the SNLR method is preferred.
The complete in vitro characterization of substrate metabolism involves determination of both a qualitative profile and quantitative parameters. The former includes identification of isozymes involved in metabolic reactions and identification of biotransformation products. Quantitative parameters generally include estimation of the maximal rate of metabolism (VMAX),1the Michaelis constant (KM), and intrinsic clearance (CLint =VMAX/KM). The latter is also, or should be, expressed in unbound form (i.e., CLu,int = CLint/fu; where, fu, is the unbound fraction of substrate in the in vitro incubation fluid milieu) (Obach, 1996, 1997).
An important practical goal of drug metabolism research is to relate in vitro findings to in vivo results, either within or across animal species. The former might include experiments conducted using a rat hepatocyte preparation and relating those results to findings from an in vivo dosing experiment in the rat. The latter would be exemplified by relating parameters obtained from a rat hepatocyte preparation to in vivo values in humans. Such within- and between-species correlations are also of interest in predicting alterations in drug metabolism (e.g., enzyme inhibition and induction).
One of the important outcomes of identifying isozymes responsible for metabolism, is the prediction and assessment of potential drug (or nutrient) interactions. The questions, “will an existing drug alter the metabolism of the new agent?” and “will the new agent alter the metabolism of existing drugs?” are only partially answered, however, by identification of the substrate isozyme responsible for metabolism. The other quantitative part of the question that needs to be answered is, “is the interaction likely to occur?” The latter is generally assessed by a comparison of the observed (or expected) plasma concentrations of the compound relative to its enzyme inhibition constant (Ki). Thus, if plasma concentrations are greater than Ki, an interaction is likely. Conversely, if the plasma concentrations are less than Ki, an interaction is unlikely.
Enzyme inhibition studies are routinely conducted to assess the presence and magnitude of drug-drug interactions. To characterize the inhibition process (i.e., competitive, noncompetitive, or uncompetitive) and to determine the inhibition constant (Ki), data are often analyzed by techniques that linearize inherently nonlinear relationships. These techniques were developed before the general use of computers and programs capable of analyzing nonlinear functions. Surprisingly, the linear forms of these relationships are in common use today, despite the ready availability of suitable computer programs. There has been increasing recent evidence of a greater reliance on nonlinear fitting routines for the analysis of enzyme kinetic data (Daigle et al., 1997;Scholten et al., 1997). Other investigators use another approach that relies upon a nonsimultaneous, nonlinear regression method in combination with linear regression (Bourrie et al., 1996; Copeland, 1996).
The aim of the present study was to compare three methods of analysis of competitive enzyme inhibition data for the estimation ofKi (as well asKM and VMAX). Simulated data sets were generated assuming a competitive inhibition model and the resulting findings compared to assess which is the better, most reliable approach to use.
Materials and Methods
Assuming that a single metabolite is produced from the substrate, metabolite formation rates were simulated using a competitive enzyme-inhibition model. These rates were generated using an Excel spreadsheet (Microsoft, Redmond, WA) and the following equation (Segel, 1975),
Normally distributed [N(0,1)] random error was added to the exact (i.e., perfect) metabolite formation rate data (vexact). The normally distributed random errors were obtained from random numbers (rn) created in Excel. The following error was added to each simulated perfect value of rate: 0.1 · rate · random number. This method corresponds to using an additive error of 10% coefficient of variation. The resulting value for rate is represented as: vobs =vexact + 0.1 ·vexact · rn; wherevobs is the value for rate that was used in the subsequent analyses.
Three different sets of parameter values were examined in this study (Table 1). Set 1 corresponds to values obtained from an in vitro study of an interaction between tolbutamide and sulfaphenazole (Bourrie et al., 1996). Set 2 corresponds to an in vitro interaction study of coumarin and pilocarpine (Bourrie et al., 1996). The two previous studies were conducted using human liver microsomes. Set 3 represents an example cited by Copeland (1996). The units have been defined here only to be consistent with the first two experimentally based literature examples. The range ofKM/Ki ratios varies from 0.085 to 613.
Three different sets of parameter values examined in study
For each of the above three sets of parameters, three complete series of experiments were conducted (in triplicate) such that each experiment comprised five inhibitor concentrations and one control (i.e., no inhibitor), with six substrate concentrations per inhibitor and control. That is, a total of 108 average rates of metabolite formation with error (vobs) were generated per set of parameters. The averages of the observed rates for the three experiments at a given substrate concentration were obtained and used in the subsequent analyses.
The above data were analyzed using the following methods.
Simultaneous Nonlinear Regression (SNLR).
The average observed rate versus substrate concentration data (in the presence and absence of inhibitors) were fit simultaneously according to the full nonlinear expression for competitive enzyme inhibition as expressed in eq. 1. This is an exercise in fitting only one complete data set. Nonlinear regression fitting was accomplished with use of the WinNonlin program (Scientific Consulting, Inc., Cary, NC) with a weighting function of 1/Y2. Two approaches were applied to this analysis. In one instance all of the data were analyzed simultaneously, as noted above, for all parameters (i.e.,VMAX, KM, andKi). In the other instance, the control data (i.e., no inhibitor) were first analyzed to obtain estimates ofVMAX and KM. Those values were then fixed in fitting the average rate data obtained from the inhibition experiments for estimation ofKi.
Another question that was addressed was the influence of the number of inhibitor concentrations on the estimated value ofKi. This effect was evaluated by deleting results from the inhibition experiments, beginning with six values and decreasing until only one inhibitor concentration was used in the analysis.
“KM,app” Method.
This method employs nonsimultaneous, nonlinear regression analyses. Each of the six independent experimental data sets, for the control and each of the five inhibitor concentrations, were fit individually by nonlinear regression to the Michaelis-Menten expression,

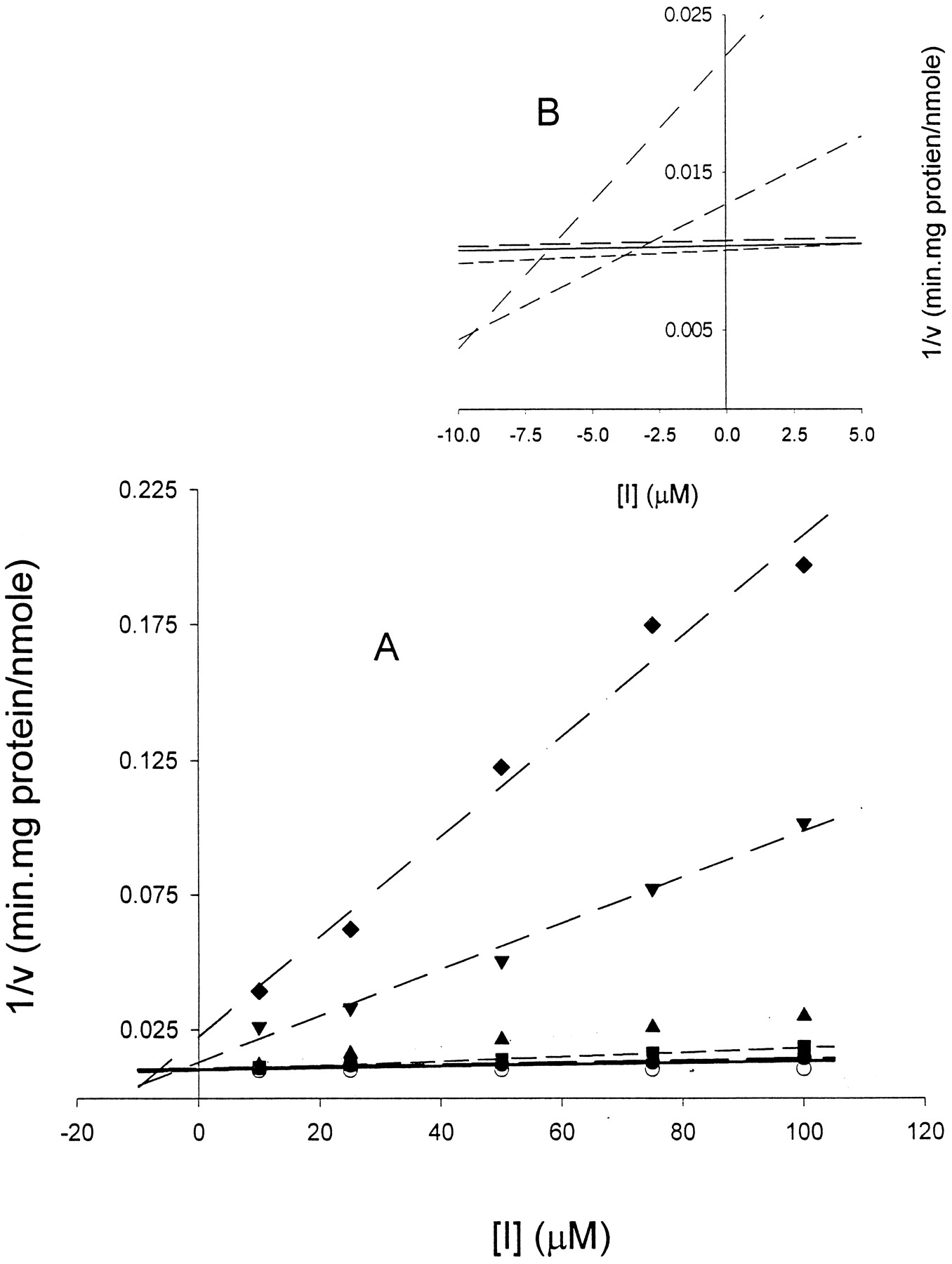
Illustration of application of KM,app method for analysis of enzyme inhibition data.
A, each line represents nonlinear regression analysis of average simulated rates of metabolite formation (v) as a function of substrate concentration [S] for parameter data set 3 (KM = 10 μM;VMAX = 100 nmol/min · mg protein;Ki = 5 μM). Individual “experimental” data sets were fit to the full Michaelis-Menten equation (see eq. 2 in text) from which estimates of KM,app andVMAX were obtained. Each point represents mean and S.D. (cross-hatched bars) of three experiments. B, plot ofKM,app/VMAXversus inhibitor concentration [I] used to estimate inhibition constant, Ki. Estimates ofKM,app/VMAX were obtained from analysis of rate data shown in A. Solid line is linear regression analysis of data. Intercept of line on x-axis represents −Ki (ca., 5 μM). Inhibitor concentrations: 0 μM (○, control), 10 μM (●), 25 μM (▪), 50 μM (▴), 75 μM (▾), and 100 μM (♦).
Estimates of Ki were obtained from the linear regression plot ofKM,app/VMAX as a function of the inhibitor concentration, [I]. Such a plot is illustrated in Fig. 1B. The equation describing this relationship is (Copeland, 1996),
The value for Ki is obtained from the intercept on the x-axis (i.e., when y = 0, [I] = −Ki) or it is calculated from the slope. The data were fit by linear regression (with a weighting function of 1/Y) and solution for the intercept provided an estimate ofKi. The STATA program (Stata Corp., College Station, TX) was used for this purpose. As with the assessment of the SNLR approach, the influence of the number of inhibitor concentrations on the resulting estimate of Ki was determined.
Dixon Method.
The Dixon (1953) plot is frequently used for both identification of the likely mechanism of enzyme inhibition and for estimation ofKi. Plots were prepared of the reciprocal of rate of metabolite formation (1/vobs) versus inhibitor concentration at each substrate concentration. The equation governing this relationship is given below,
A, Dixon plot of reciprocal rates of metabolite formation (1/v) as a function of inhibitor concentration [I].
Each line represents linear regression analysis of reciprocal of average simulated rates of metabolite formation for different substrate concentrations as a function of inhibitor concentration. These simulated data correspond to parameter data set 3 (KM = 10 μM;VMAX = 100 nmol/min · mg protein;Ki = 5 μM). Substrate concentrations: 10 μM (♦), 25 μM (▾), 100 μM (▴), 250 μM (▪), 500 μM (●), and 1000 μM (○). B, enlarged view of negativex-axis from graph A indicating that there are several intersections of lines.
Results
Table 2 summarizes the findings of this study for one of the three sets of parameter values (set 3;KM/Ki = 2.0) and for the three methods of analyses examined. For the SNLR andKM,app methods there are three values ofKi listed under the column headings, Fixed and Varying and the resulting means and S.D.s of those values. The term “fixed” indicates that the control data were analyzed by nonlinear regression to obtain the best fitting values forVMAX and KM. Those values were then fixed in the subsequent SNLR analysis of all of the data (i.e., control and inhibition data). The term “varying” indicates that values for VMAX andKM were obtained from the simultaneous fit of all of the data (including the control experiment) and there was no attempt made to fix the values.
Estimates of Ki (μM) obtained from three methods of data analysis applied to one set of parameters2-a
Each of the Ki values listed was obtained from the analysis of a complete data set that included triplicate determinations of metabolite formation rates per substrate concentration. Thus, the values 4.71, 4.60, and 4.92 (under SNLR, Fixed column) are Ki estimates obtained from three different data sets, each involving triplicate estimations of rate versus substrate concentrations for a control and five inhibitor concentrations. Furthermore, the table is divided into rows according to the number of inhibitor concentrations used in the analysis. As an example, 4.74 (±0.16) and 4.95 (±0.27) are the means and S.D.s forKi when the SNLR method is used to analyze the data from five inhibitor concentrations and one control experiment and when VMAX andKM are either fixed or allowed to vary, respectively.
Considering the SNLR results, the mean estimates ofKi are not very different from the perfect value of 5.0; regardless of whether VMAX andKM were fixed or allowed to vary. Furthermore, the values for Ki do not vary greatly from the correct number as one moves down the table; that is, as fewer inhibition curves are generated. The S.D.s, however, do increase as the total number of experiments are reduced. Thus, using only the control experiment and one inhibition curve, the meanKi value is 4.71 (range, 3.91–5.61) with a coefficient of variation of 18%. The latter range and variation are considerably greater than those associated with estimates ofKi that rely upon more inhibition curves.
The column designated KM,app is divided into two components, as with the SNLR method, one in which the value for VMAX was fixed and the other in which it was allowed to vary. The influence of the use of a weighting function (no weight or 1/Y) for the linear regression analysis of theKM,app/VMAXversus [I] data (as shown in Fig. 1B) is presented in the table. The mean values for Ki when a weighting function is applied is shown in parentheses. The mean estimates of Ki are similar to the correct value of 5.0 and weighting generally improves the estimate and reduces its variance. As noted for the SNLR results, the S.D.s increase as one moves down the column; that is, as fewer inhibition curves are used in estimation of Ki.
The results from the Dixon analysis are shown on the right side of Table 2. Each column corresponds to a substrate concentration and the values for Ki are listed for each data set. The values listed for Ki were obtained from the intersection of the line described by that substrate concentration and the line having the least slope (the greatest substrate concentration; [S] = 1000 μM). Thus, the average value forKi of 4.28 μM (under the column [S] = 10 μM) is the average of the three intersections of the lines described by that substrate concentration and the line of substrate concentration [S] = 1000 μM. The lines corresponding to the lowest substrate concentrations (these are the lines with the steepest slope) provide reasonable but highly variable estimates ofKi. The best estimates ofKi were obtained from the intersection of the lines representing [S] = 25 and [S] = 1000 μM. The corresponding values of Ki ranged from 3.21 to 8.06 with a mean of 5.37 ± 2.47 μM. The higher the substrate concentration, going from left to right in the table, the less reliable the values for Ki; indeed, in some instances, negative values were obtained, which is clearly meaningless. Applying a weighting function to the regression analysis of the Dixon plot did not substantially improve the estimates ofKi and, therefore, only the estimates obtained without weighting are presented. The graph depicting the Dixon analysis is illustrated in Fig. 2.
Table 3 further summarizes the results of the analyses for all three sets of parameter values. The data are presented as ranges of values and incorporate the identical, extensive analyses as indicated in Table 2. The values forKi encompass a rather narrow range and approximate the correct value for each data set when the data are analyzed by either the SNLR or KM,appmethods. The Dixon method, on the other hand, provides for wide variation in values; often different by an order of magnitude. The Dixon method gave the best estimates of Kifor the strongest inhibitor (Ki = 0.3) but only in two cases; 0.35 ± 0.05 and 0.25 ± 0.16 μM from intersections of lines drawn at [S] = 200 and 500 μM with the line of [S] = 1000 μM, respectively. Furthermore, the Dixon method provides a range of Ki values that encompass zero (i.e., negative values).
Summary of range of estimates for Ki,VMAX, and KM obtained from three methods of data analysis applied to three sets of parameters
The ranges of the recovered values for KMand VMAX were rather narrow and all ranges encompassed the correct value. Although the ranges were somewhat less variable for the SNLR method, the KM,appmethod provided essentially identical ranges. No attempt was made to estimate KM andVMAX from the Dixon analysis.
Discussion
The purpose of this study was to examine and contrast three different methods that are used for the analysis of in vitro enzyme inhibition data to obtain estimates of the inhibition constant,Ki. The primary questions posed were, which procedure: a) provides the most accurate and least variable estimates of Ki (as well asKM and VMAX); b) is least affected by a wide range of enzyme parameter values; c) requires the least amount of information (and, therefore, a minimal amount of experimentation); and d) is the easiest to implement and use routinely?
There were two issues responsible for prompting these questions. First, although it is generally well known that linear representations of inherently nonlinear relationships (e.g., Lineweaver-Burk plot) will often provide poor estimates of parameter values, there is ample evidence in the recent literature of data analysis using linearized expressions. A specific example is the analysis of enzyme inhibition data with use of, for example, the Dixon plot. Although the latter is often relied upon in making decisions concerning the mechanism of inhibition, it would not be expected to provide robust estimates of the inhibition constant, Ki. The surprising aspect of this situation is that we no longer need to rely upon linearized analyses, as was necessary before the availability of computers (mainframes or personal) and the necessary software packages capable of performing nonlinear regression analyses. Personal computers and software packages are now commonplace and, although there are indications of many groups now using these more sophisticated and appropriate methods of analyses, the current literature is replete with examples where the linearized methods are still being relied upon. Perhaps this is simply an expression of old habits disappearing slowly.
The second issue is best understood with reference to the phenomenal efforts being made in the drug discovery process in the pharmaceutical industry. The creation of large numbers of new chemical entities, especially as a result of efforts from combinatorial chemistry, has created the need for high-throughput screening for numerous drug properties/characteristics such as pathways of metabolism and potential drug-drug interactions. In that regard, the current investigation might prove useful if we were able to identify approaches to data analysis that are not only robust but that are able to reduce the current experimental burden in in vitro screening for interactions.
The results of this investigation provide several answers to the basic questions posed. Regarding the method of analysis of enzyme inhibition data assuming, as we have here, a competitive inhibition model, the classic approach of Dixon is the least acceptable among the three methods examined. The approach used here to estimateKi from a Dixon analysis is that suggested by Segel (1975): determine the point of intersection of substrate lines either with the highest substrate line ([S] = 1000 μM, in this case) or with a horizontal line drawn through the value of 1/VMAX on the y-axis (assuming that VMAX is known). Although the Dixon plot may serve to suggest the most likely mechanism of enzyme inhibition and provide for initial estimates ofKi, it does not share the desirable attributes of the alternative methods: accurate and robust estimates ofKi, less demand for experimental data, and simplicity. The latter points are addressed below. Even if one is only interested in a “ballpark” estimate ofKi, the Dixon approach may provide values that are incorrect by an order of magnitude or greater.
The simulations conducted here and analyzed by the Dixon method indicate that the substrate concentration used will have a marked effect on the accuracy of the Ki value. As noted in Table 2, the higher the substrate concentration (moving from left to right in the table), the greater the error and variance in estimation of Ki. This problem can be seen graphically in Fig. 2B. Furthermore, negative values are sometimes encountered: a meaningless result. The most accurate but still variable estimates of Ki appear to occur at low substrate concentrations ([S] = 10 or 25 μM). For the three parameter sets evaluated here and summarized in Table 3, the Dixon method results in ranges of values that encompass zero.
In marked contrast to the Dixon method and, we suspect, other approaches that are a combination of linearized forms of the enzyme inhibition relationship, both the SNLR and theKM,app methods do an excellent job of accurately estimating Ki. The ranges of estimates of Ki encompass the correct value, never include zero, and there is generally less than a 2-fold range in values (Table 3). The accuracy in estimation ofKi appears not to depend upon the enzyme parameter values as a wide range of values were used (i.e., parameter sets 1–3, Table 3). Furthermore, those methods perform very well in accurately recovering values of VMAX andKM. As noted in Table 3, the ranges for the estimated values of VMAX andKM are narrow and always encompass the correct value.
Of the two nonlinear approaches examined here, the SNLR method, is recommended because it is easy to implement and it performs the analysis using the full nonlinear expression for enzyme inhibition. In contrast, the other nonlinear approach, referred to here asKM,app, although providing equally good estimates of all three parameters, is more demanding of analysis and requires a two-step procedure. That method is more demanding of analysis in that each of the control and inhibitor curves must be individually fit by nonlinear regression to obtain estimates ofKM and VMAX(from the control data) and values forKM,app (with or without estimates ofVMAX from the inhibition curves; Fig. 1A). The latter values and KM must then be plotted on a linear scale for an estimate ofKi to be obtained (Fig. 1B). In the SNLR approach, all parameter values are obtained from a single data fitting session.
The SNLR and the KM,app methods, in addition to providing more accurate and reliable estimates ofKi in comparison with the Dixon method, will permit a reduction in the amount of experimental data needed. This is exemplified in Table 2 where, moving down the table of values, the number of inhibitor concentrations have been reduced from a maximum of five sets of inhibitor curves to only one inhibitor curve for the SNLR method or two inhibitor curves for theKM,app method. In the former case and using our experimental paradigm, this would translate to reducing the experimental burden from 270 values (i.e., 6 substrates × 5 inhibitor concentrations × 3 experiments × 3 determinations) to 54 values (i.e., 6 substrates × 1 inhibitor concentration × 3 experiments × 3 determinations). A control experiment would need to be added to each of the preceding designs. Although the paradigm selected here for simulation purposes is likely to be more extensive and demanding than one chosen to be practical by an experimenter, there will be, nonetheless, a reduction in the total number of experiments and an accompanying savings of time and costs. We are not endorsing the use of only one inhibitor concentration curve at this time, because we have conducted only limited simulations and have not yet experimentally tested this idea. Our limited results (Table 2) suggest that such an approach would provide reasonably accurate but variable estimates ofKi. The KM,appmethod could in theory also only require one inhibitor curve, because this would provide two points to form a straight line in the linear analysis to calculate Ki. We chose, however, to use two inhibitor curves as the minimum number, which will provide three points (including the control) in the linear analysis.
It is, in fact, possible to use an even less demanding experimental design to obtain reasonable estimates of Ki(as well as KM andVMAX). For example, rather than conduct an entire inhibition curve (i.e., one inhibitor concentration with a range of substrate concentrations), which is currently our minimal experimental design, would it be feasible to use (in addition to the control experiment) only one substrate concentration with one inhibitor concentration in triplicate (i.e., only three values plus the control experiment)? Preliminary evidence from simulations suggests that the latter is, in fact, plausible and will provide reasonable estimates of the parameter values (Y. Pak, T.K., H.B. and M.M., unpublished observations).
In conclusion, we conducted extensive simulations to compare three methods of analysis that may be used for estimation of the inhibition constant, Ki, from data obtained in an enzyme inhibition experiment. The two methods that use a nonlinear expression more accurately estimate Kias well as values for KM andVMAX in comparison with the linearized approach of Dixon. The latter technique is not recommended for that purpose. The nonlinear approaches also offer, compared with the Dixon method, the potential advantage of substantial reduction in experimental time and costs. The latter is being pursued to determine the minimal experimental design that is compatible with estimation of accurate parameter values. We have not, of course, exhausted the possible combinations of parameter values in our simulations. Nor have we examined the effect of an introduction of larger random errors into the simulated data. However, the final conclusions will most likely remain the same: the nonlinear approach to the estimation of enzyme kinetic parameters is expected to be more accurate and robust.
Note Added in Press:
We recently came across a paper by Nimmo and Atkins [Biochem J (1976)157:489–492] who analyzed data in a manner similar to that reported in this communication. Unfortunately, that paper appears to have been largely ignored by most investigators. Although there are differences to be found between these reports, those investigators deserve credit for the earliest reporting, to our knowledge, of what we have referred to as the SNLR method (their “direct” method).
Footnotes
-
Send reprint requests to: Michael Mayersohn, College of Pharmacy, The University of Arizona, Tucson, AZ 85721. E-mail:mayersohn{at}pharmacy.arizona.edu
-
This work was supported by grants from the National Institute on Drug Abuse (DA08094), National Institute of Environmental Health Sciences (The Southwest Environmental Health Sciences Center, P30-ES06694), and a contract from the National Institute of Environmental Health Sciences (NO1-ES35367).
- Abbreviations used are::
- SNLR
- simultaneous nonlinear regression
- KM,app
- nonsimultaneous nonlinear regression
- Ki
- inhibition constant
- KM
- Michaelis constant
- VMAX
- maximal rate of metabolism
- Received August 14, 1998.
- Accepted March 2, 1999.
- The American Society for Pharmacology and Experimental Therapeutics




{kind=link}
{kind=link}